4. Random Forest
1. Random Forest
랜덤 포레스트는 여러 개의 의사결정 나무(Decision Tree)를 생성하고 그들의 예측을 종합하여 최종 결과를 도출하는 앙상블 학습 방법이다.
각각의 트리는 데이터의 서브셋과 특성의 서브셋을 사용하여 학습되며, 이를 통해 모델의 다양성을 확보하고 과적합을 방지한다.
장점
- 높은 예측 정확도
- 과적합에 강한 내성
- 특성 중요도 평가 가능
- 병렬 처리가 가능하여 학습 속도가 빠름
단점
- 모델의 해석이 어려움
- 메모리 사용량이 큼
- 학습 데이터가 많이 필요함
2. Random Forest의 작동 원리
1. 부트스트랩 샘플링으로 여러 개의 훈련 데이터셋 생성
2. 각 노드에서 무작위로 선택된 특성들만 사용하여 분기
3. 각 트리의 예측을 집계하여 최종 결과 도출 (분류는 다수결, 회귀는 평균)
Random Forest의 주요 파라미터
- n_estimators
- 생성할 트리의 개수
- 일반적으로 많을수록 좋지만, 계산 비용이 증가
- max_depth
- 트리의 최대 깊이
- 과적합 제어에 중요한 파라미터
- max_features
- 각 분기에서 고려할 특성의 수
- 기본값은 분류의 경우 sqrt(n_features)
3. 코드 실습
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_moons
# step 1: 데이터 생성
X, y = make_moons(n_samples=1000, noise=0.2, random_state=42)
# step 2: Random Forest 모델 학습
rf_clf = RandomForestClassifier(n_estimators=100,
max_depth=5,
random_state=42)
rf_clf.fit(X, y)
# step 3: 결정 경계 시각화
xx, yy = np.meshgrid(np.linspace(X[:, 0].min()-0.5, X[:, 0].max()+0.5, 100),
np.linspace(X[:, 1].min()-0.5, X[:, 1].max()+0.5, 100))
Z = rf_clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]
Z = Z.reshape(xx.shape)
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.scatter(X[y==0][:, 0], X[y==0][:, 1], color='royalblue', alpha=0.8, label='Class 0')
plt.scatter(X[y==1][:, 0], X[y==1][:, 1], color='tomato', alpha=0.8, label='Class 1')
plt.title("Data Distribution")
plt.grid()
plt.legend()
plt.subplot(1,2,2)
plt.contourf(xx, yy, Z, alpha=0.4, cmap='RdYlBu')
plt.scatter(X[y==0][:, 0], X[y==0][:, 1], color='royalblue', alpha=0.8, label='Class 0')
plt.scatter(X[y==1][:, 0], X[y==1][:, 1], color='tomato', alpha=0.8, label='Class 1')
plt.title("Random Forest Decision Boundary")
plt.grid()
plt.legend()
plt.tight_layout()
plt.show()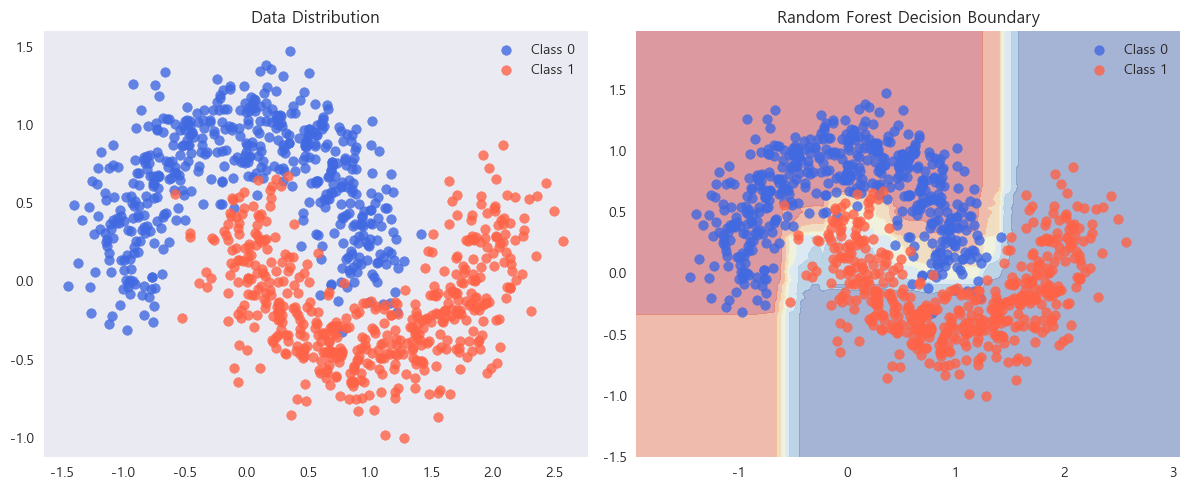
'Machine Learning > Model' 카테고리의 다른 글
| 7. CatBoost (0) | 2024.10.02 |
|---|---|
| 6. LightGBM (0) | 2024.04.16 |
| 5. XGBoost (0) | 2024.02.07 |
| 3. SVM (0) | 2024.01.09 |
| 2. Logistic Regression (0) | 2023.12.25 |
| 1. K-NN (K-Nearest Neighbor) 알고리즘 (0) | 2023.12.18 |


댓글